Chapter 3 Linear Regression
3.1 Conceptual Exercises
3.1.1 Exercise 1.
Recall the model for the Advertising data:
\[sales = \beta_0 + \beta_1 \times TV + \beta_2 \times radio + \beta_3 \times newspaper + \epsilon\]
After fitting the model, we found out this results:
| Coefficient | Std. error | t-statistic | p-value | |
|---|---|---|---|---|
| Intercept | 2.939 | 0.3119 | 9.42 | < 0.001 |
| TV | 0.046 | 0.0014 | 32.81 | < 0.001 |
| radio | 0.189 | 0.0086 | 21.89 | < 0.001 |
| newspaper | -0.001 | 0.0059 | -0.18 | 0.8599 |
The null hypotheses to which the p-values given in the table correspond is
\[H_0 : \beta_0 = \beta_1 = \beta_2 = \beta_3 = 0\]
versus
\[H_1 : \beta_0 \neq 0, \beta_1 \neq 0, \beta_2 \neq 0 ~\text{and}~ \beta_3 \neq 0\]
This p-values means that the two features TV and radio are significant for the Advertising data. However, the feature newspaper is not statistically significant. So, this varible does not have an influence on the sales.
3.1.2 Exercise 2.
In both the \(K\) nearest neighbors regression and classification, the beginning point is to identifies the \(K\) points that are the closest to a given points \(x_0\). Let call this set \(\mathcal{N}_0\). But, the quantity of interest is to not same. In the regression setting, we are interested by the estimation of \(\hat{f}(x_0)\). This is done by averaging the values of the \(K\) closest points of \(x_0\). \[\hat{f}(x_0) = \frac{1}{K}\sum_{x_i \in \mathcal{N}_0} y_i\]
In the classification setting, we first aim to predict the probability of belonging to some class \(j\). This is done by counting the proportion of the \(K\) closest points of \(x_0\) that belong to the class \(j\).
\[\mathbb{P}(Y = j \mid X = x_0) = \frac{1}{K}\sum_{x_i \in \mathcal{N}_0}\mathcal{1}(y_i = j)\]
Finally, using the Bayes rules, we classify \(x_0\) in the class with the largest probability.
3.1.3 Exercise 3.
The linear model is:
\[Y = \widehat{\beta}_0 + \sum_{i = 1}^{5}\widehat{\beta}_iX_i.\]
- Question (a)
For a fixed value of IQ (\(X_2\)) and GPA (\(X_1\)), females earn more on average than males because the coefficient of Gender (\(X_3\)) is positive. However, for a fixed value of IQ (\(X_2\)) and GPA (\(X_1\)), males earn more on average than females provided that the GPA is high enough (larger than 3.5) because the coefficient of the interaction between GPA and Gender (\(X_5\)) is negative.
- Question (b)
The salary of a woman with IQ of 110 and a GPA of 4.0 is (in thousands of dollars):
\[Y = 50 + 20\times 4.0 + 0.07\times 110 + 35\times 1 + 0.01\times 4.0\times 110 - 10\times 4.0\times 1 = 137.1.\]
- Question (c)
With only the value of \(\widehat{\beta}_4\), we can not conclude on the evidence of an GPA/IQ interaction effect on the starting salary after graduation even if this value is very small. To test that, we should compute the F-statistic and the corresponding p-value. If the p-value is very low (usually under 0.05), there is a clear evidence of the relationship between the GPA/IQ interaction and the salary.
3.1.4 Exercise 4.
- Question (a) and (b)
The true relationship between \(X\) and \(Y\) is linear. So, the cubic regression model will overfit. For the training, we expect the RSS for the cubic model to be lower than the one of the linear model because it will follow the noise more closely. However, on the test set, it should be the opposite.
- Question (c) and (d)
The true relationship between \(X\) and \(Y\) is not linear. As before, the cubic regression should have a lower train RSS because this model is more flexible than the linear model. However, we can not tell which one will be lower for the test set because it depends on “how far the data is from linear”. If the true relationship is almost linear, the test RSS will be lower for the linear model and conversely, if the true relationship is closer to the cubic model, the test RSS will be lower for the cubic model.
3.1.5 Exercise 5.
\[ \widehat{y}_i = x_i\widehat{\beta} = x_i \frac{\sum_{j=1}^n x_jy_j}{\sum_{k=1}^n x^2_k} = \sum_{j=1}^n\frac{x_jx_i}{\sum_{k=1}^n x^2_k}y_j\]
So, \(a_j = \frac{x_jx_i}{\sum_{k=1}^n x^2_k}\). We interpret this result by saying that the fitted values from linear regression are linear combinations of the response values.
3.1.6 Exercise 6.
The simple linear model is: \(y_i = \beta_0 + \beta_1x_i\). The estimator of \(\beta_0\) and \(\beta_1\) are:
\[\widehat{\beta_0} = \bar{y} - \widehat{\beta_1}\bar{x} \quad\text{and}\quad \widehat{\beta_1} = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^n (x_i - \bar{x})^2}\]
Let’s predict the value of \(y_i\) for \(x_i = \bar{x}\).
\[\widehat{\beta_0} + \widehat{\beta_1}\bar{x} = \bar{y} - \widehat{\beta_1}\bar{x} + \widehat{\beta_1}\bar{x} = \bar{y}\]
So, the least squares line always passes through the point \((\bar{x}, \bar{y})\).
3.1.7 Exercise 7.
Assume that \(\bar{x} = \bar{y} = 0\).
\[R^2 = 1 - \frac{\sum(y_i - \widehat{y}_i)^2}{\sum y_i^2} = \frac{\sum y_i^2 - \sum y_i^2 + 2\sum y_i\widehat{y}_i - \sum\widehat{y}_i^2}{\sum y_i^2}\]
We know that \(\widehat{y}_i = x_i\widehat{\beta}\). So
\[ R^2 = \frac{2\sum y_ix_i\widehat{\beta} - \sum x_i^2\widehat{\beta^2}}{\sum y_i^2} = \widehat{\beta}\frac{2\sum y_ix_i - \sum x_i^2\widehat{\beta}}{\sum y_i^2}\]
Replace \(\widehat{\beta}\) by \(\frac{\sum y_ix_i}{\sum x_i^2}\), and \(\sum x_i^2\widehat{\beta} = \sum x_iy_i\). Finally,
\[R^2 = \frac{2(\sum x_iy_i)^2 - (\sum x_iy_i)^2}{\sum x_i^2\sum y_i^2} = \frac{(\sum x_iy_i)^2}{\sum x_i^2\sum y_i^2} = Corr^2\]
In the case of simple linear regression of \(Y\) onto \(X\), the \(R^2\) statistic is equal to the square of the correlation between \(X\) and \(Y\).
3.2 Applied Exercises
3.2.1 Exercise 8.
This exercise is about fitting a simple linear model to the Auto dataset. It contains 392 observations of 9 variables about vehicles. For a description of the variables, please refer to R by typing help(Auto) after loading the package ISLR.
- Question (a)
- Formula: mpg ~ horsepower
- Residuals
- Coefficients
- Residual standard error: 4.906 on 390 degrees of freedom.
- Multiple \(R^2\): 0.606.
- Adjusted \(R^2\): 0.605.
- F-statistic: 599.718 on 1 and 390, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 333 | 30.5 | 0 | 24 | -13.57 | -6.99 | -5.97 | -3.26 | -0.34 | 2.76 | 7.11 | 8.77 | 16.92 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 39.93586 | 0.71750 | 55.65984 | < 2.22e-16 |
| horsepower | -0.15784 | 0.00645 | -24.48914 | < 2.22e-16 |
We test the hypothesis \(H_0: \beta_1 = 0\). We use the F-statistic to determine whether or not we should reject the null hypothesis. As the p-value associated with the the F-statistic is very low, there is a clear evidence of a relationship between mpg and horsepower. There are two measures of model accuracy to characterize how strong is the relationship between the response and the variable, the RSE and the \(R^2\). For the linear model, the RSE is 4.91 mpg. The mean value for mpg is 23.45, it indicates a percentage error of roughly 21%. Then, the \(R^2\) statistic is equal to 0.61. So, horsepower explains roughly 61% of the variance in mpg. The variable horsepower has a negative relationship with the response mpg because \(\beta_1 < 0\). The predicted value of mpg for horsepower = 98 is 24.47. The 95% confidence interval is (23.97, 24.96) and the 95% prediction interval is (14.81, 34.12).
- Question (b)
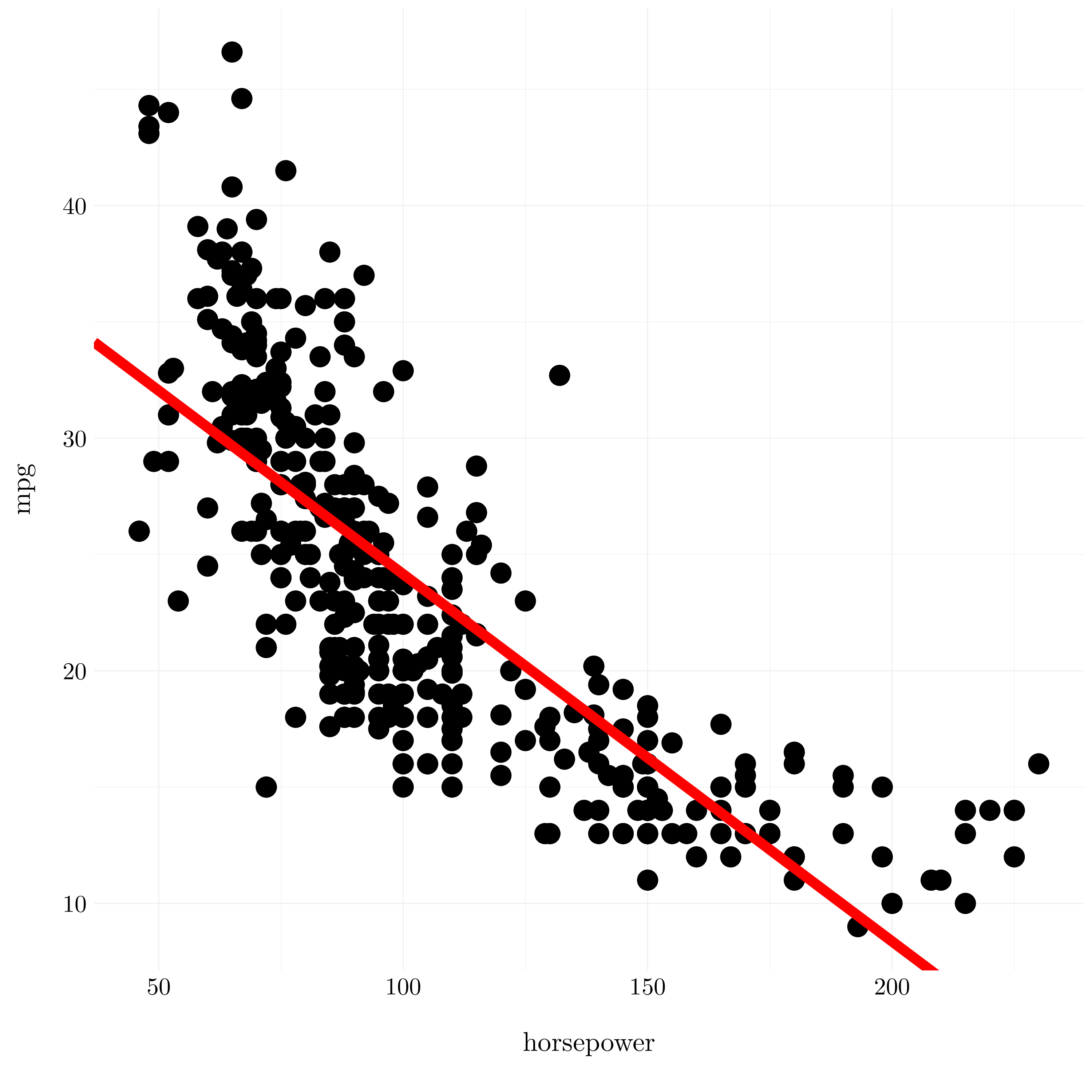
Figure 3.1: Least square regression plot for the auto dataset.
- Question (c)
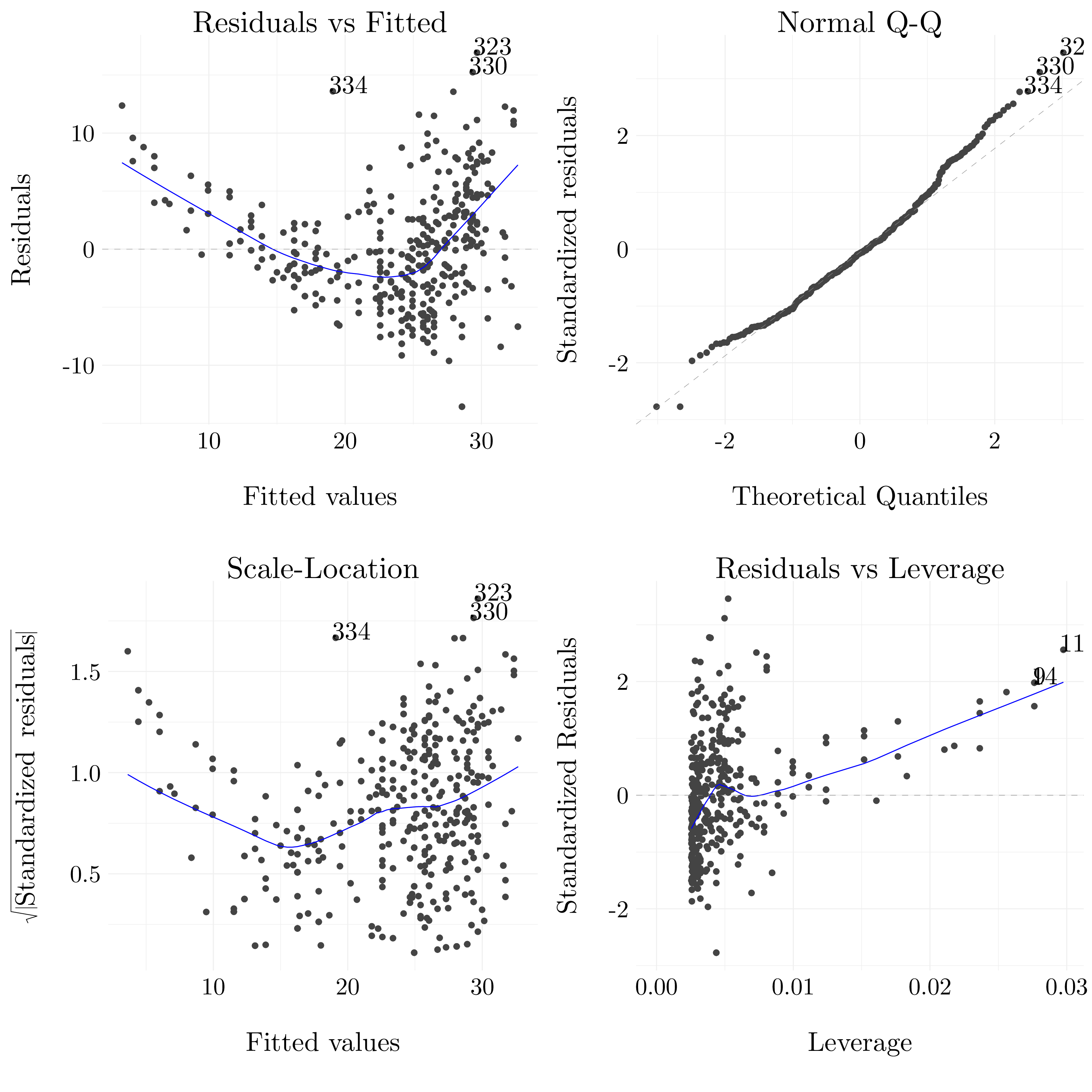
Figure 3.2: Diagnostic plots of the least square regression fit.
The plot of the fitted values agains the residuals shows a non-linear pattern in the data. So, non-linear transformation of the data, such as a quadratic transformation, could improve the fit. It does not seem to have another trouble with the fit, maybe one observation with a quite large Cook distance but that’s all.
3.2.2 Exercise 9.
This exercise is about fitting a multiple linear model to the Auto dataset. It contains 392 observations of 9 variables about vehicles. For a description of the variables, please refer to R by typing help(Auto) after loading the package ISLR.
- Question (a)
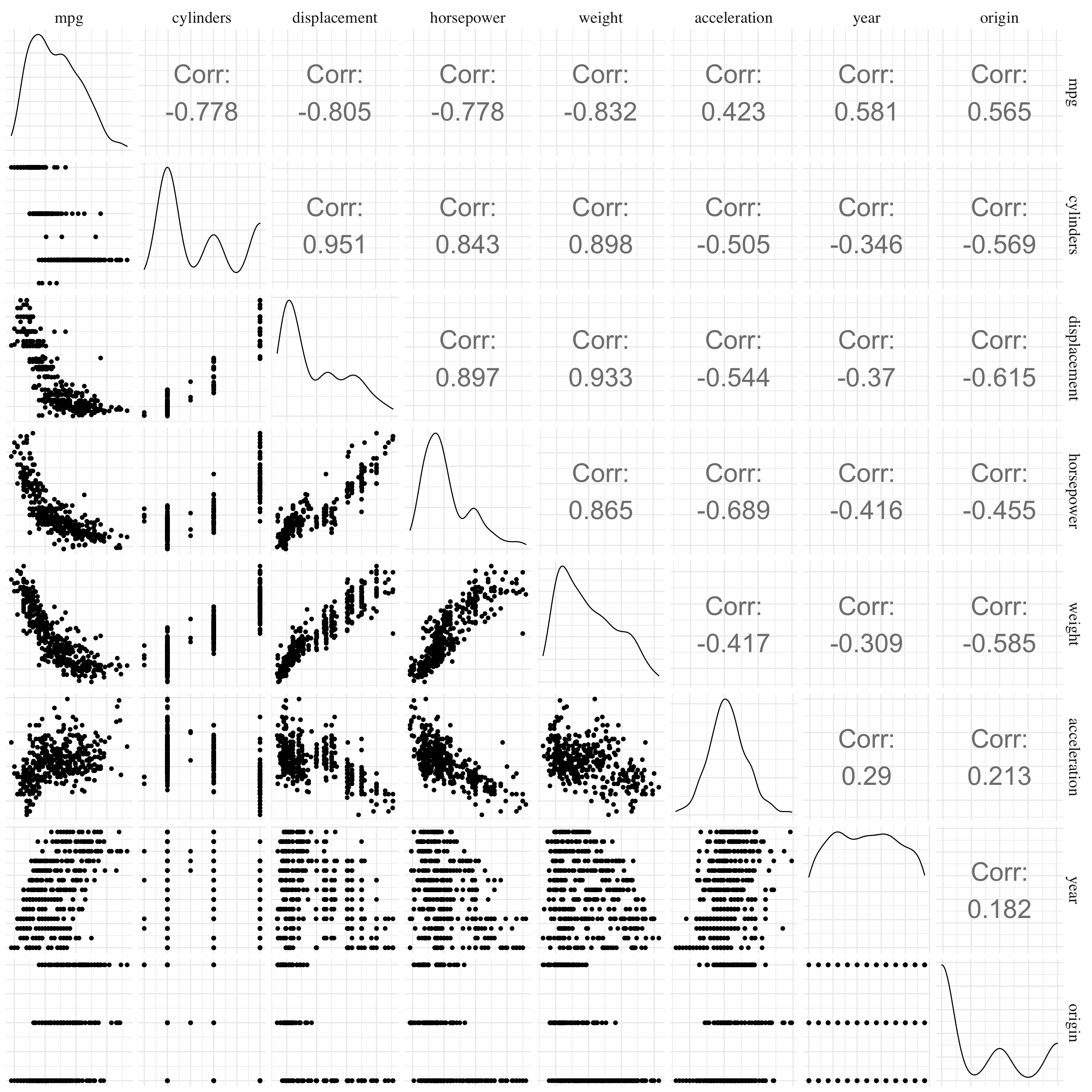
Figure 3.3: Scatterplot matrix.
- Question (b)
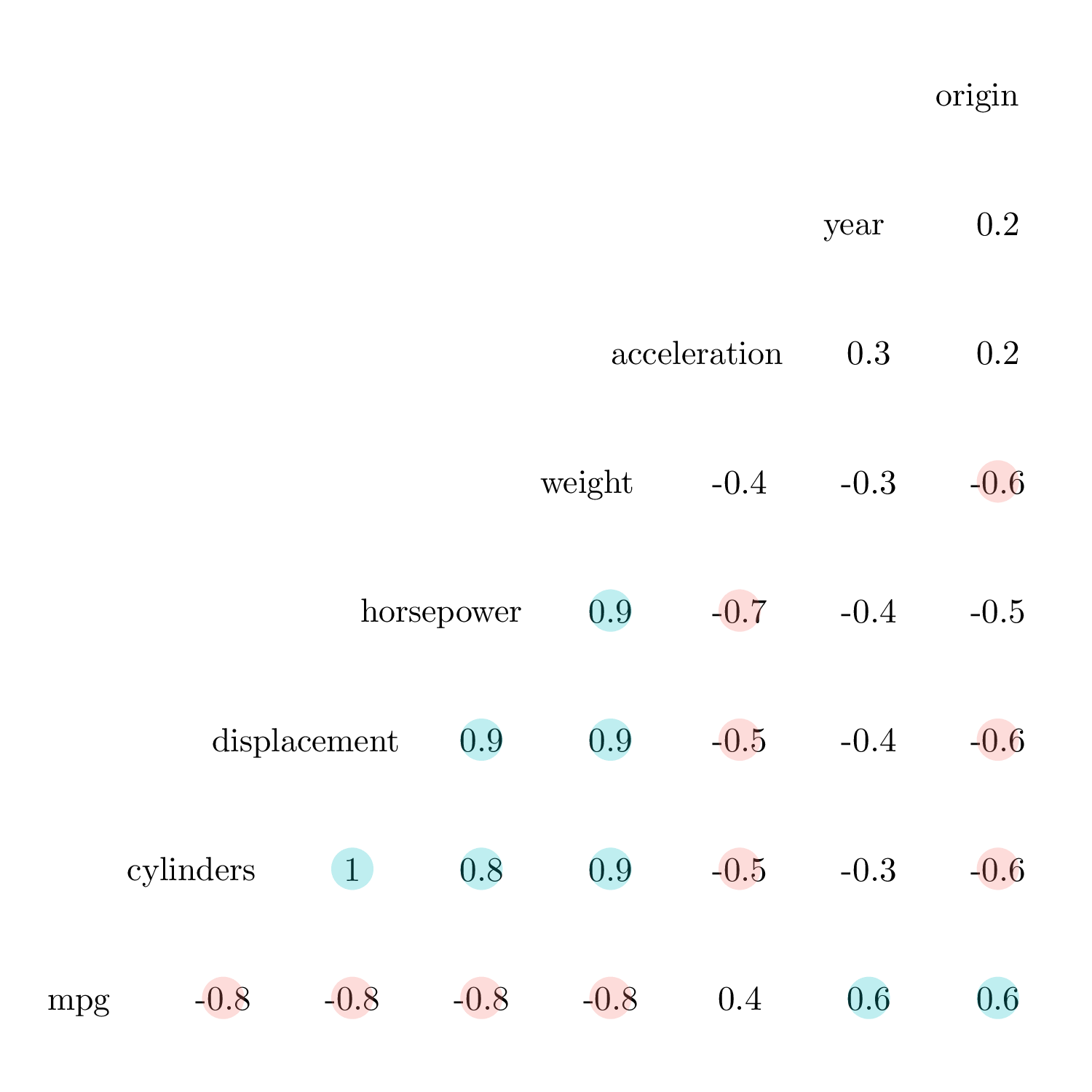
Figure 3.4: Correlation plot.
- Question (c)
- Formula: mpg ~ .
- Residuals
- Coefficients
- Residual standard error: 3.328 on 384 degrees of freedom.
- Multiple \(R^2\): 0.821.
- Adjusted \(R^2\): 0.818.
- F-statistic: 252.428 on 7 and 384, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 392 | 22.65 | 0 | 10.88 | -9.59 | -5.09 | -3.79 | -2.16 | -0.12 | 1.87 | 3.79 | 5.27 | 13.06 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -17.21843 | 4.64429 | -3.70744 | 0.00024018 |
| cylinders | -0.49338 | 0.32328 | -1.52615 | 0.12779647 |
| displacement | 0.01990 | 0.00752 | 2.64743 | 0.00844465 |
| horsepower | -0.01695 | 0.01379 | -1.22951 | 0.21963282 |
| weight | -0.00647 | 0.00065 | -9.92879 | < 2.22e-16 |
| acceleration | 0.08058 | 0.09884 | 0.81517 | 0.41547802 |
| year | 0.75077 | 0.05097 | 14.72880 | < 2.22e-16 |
| origin | 1.42614 | 0.27814 | 5.12749 | 4.6657e-07 |
We have fitted a multiple regression model of mpg onto all the other variables in the auto dataset. In order to say that there is a relationship between the features and the response, we should test the hypothesis of all \(\beta_i = 0\). For the model, the p-value associated with the F-statistic is less than \(2\times 10^{-16}\). So, there is a clear evidence of a relationship between mpg and the features. There are four variables that have a statistically significant relationship with the reponse (because they have a very low p-value). These variables are displacement, weight, year and origin. The coefficient for the year variable suggest that the mpg grows with the year, so recent cars consume less than old cars.
- Question (d)
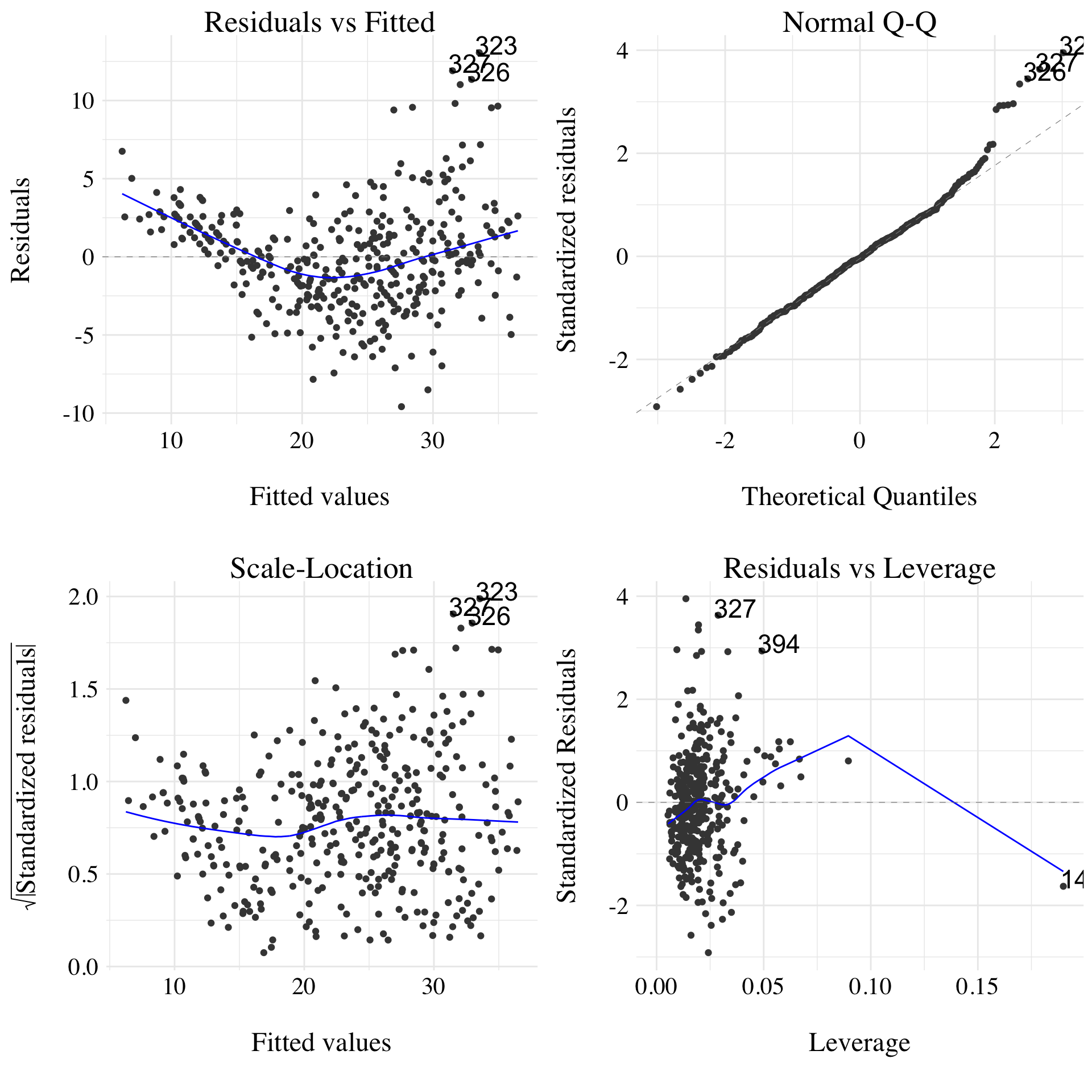
Figure 3.5: Diagnotistic plots of the multiple least square regression fit.
There is a little trend in the residuals, meaning that the linear model may not be the best model to fit on the data. Moreover, the variance of error terms seems to be non-constant. Based on this two observations, some transformation of the data could be a good idea. There is no outliers, but the point 14 appears to be a high leverage point.
- Question (e)
# Recall that cylinders:year stands for the inclusion of the interaction term between
# cylinders and years in the regression. cylinders*year adds the cylinders, year and
# cylinders:year to the model. .:. adds all the interactions to the model and .*. adds
# all the variable and their interaction to the model.
lm_model_int <- lm(mpg ~ .*., data = auto)
lm_model_int %>% summary() %>% print_summary_lm()- Formula: mpg ~ . * .
- Residuals
- Coefficients
- Residual standard error: 2.695 on 363 degrees of freedom.
- Multiple \(R^2\): 0.889.
- Adjusted \(R^2\): 0.881.
- F-statistic: 104.2 on 28 and 363, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 392 | 18.77 | 0 | 6.74 | -7.63 | -4.12 | -3.2 | -1.45 | 0.06 | 1.27 | 2.73 | 4 | 11.14 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 35.47889 | 53.13579 | 0.66770 | 0.5047479 |
| cylinders | 6.98858 | 8.24797 | 0.84731 | 0.3973815 |
| displacement | -0.47854 | 0.18935 | -2.52722 | 0.0119207 |
| horsepower | 0.50343 | 0.34700 | 1.45082 | 0.1476933 |
| weight | 0.00413 | 0.01759 | 0.23490 | 0.8144183 |
| acceleration | -5.85917 | 2.17362 | -2.69558 | 0.0073536 |
| year | 0.69743 | 0.60967 | 1.14395 | 0.2533996 |
| origin | -20.89557 | 7.09709 | -2.94424 | 0.0034459 |
| cylinders:displacement | -0.00338 | 0.00646 | -0.52412 | 0.6005130 |
| cylinders:horsepower | 0.01161 | 0.02420 | 0.47993 | 0.6315682 |
| cylinders:weight | 0.00036 | 0.00090 | 0.39918 | 0.6899953 |
| cylinders:acceleration | 0.27787 | 0.16642 | 1.66969 | 0.0958433 |
| cylinders:year | -0.17413 | 0.09714 | -1.79250 | 0.0738852 |
| cylinders:origin | 0.40217 | 0.49262 | 0.81638 | 0.4148169 |
| displacement:horsepower | -0.00008 | 0.00029 | -0.29434 | 0.7686659 |
| displacement:weight | 0.00002 | 0.00001 | 1.68205 | 0.0934193 |
| displacement:acceleration | -0.00348 | 0.00334 | -1.04107 | 0.2985339 |
| displacement:year | 0.00593 | 0.00239 | 2.48202 | 0.0135156 |
| displacement:origin | 0.02398 | 0.01947 | 1.23200 | 0.2187484 |
| horsepower:weight | -0.00002 | 0.00003 | -0.67321 | 0.5012433 |
| horsepower:acceleration | -0.00721 | 0.00372 | -1.93920 | 0.0532521 |
| horsepower:year | -0.00584 | 0.00394 | -1.48218 | 0.1391606 |
| horsepower:origin | 0.00223 | 0.02930 | 0.07619 | 0.9393091 |
| weight:acceleration | 0.00023 | 0.00023 | 1.02518 | 0.3059597 |
| weight:year | -0.00022 | 0.00021 | -1.05568 | 0.2918156 |
| weight:origin | -0.00058 | 0.00159 | -0.36379 | 0.7162292 |
| acceleration:year | 0.05562 | 0.02558 | 2.17427 | 0.0303306 |
| acceleration:origin | 0.45832 | 0.15666 | 2.92555 | 0.0036547 |
| year:origin | 0.13926 | 0.07399 | 1.88212 | 0.0606197 |
Three interactions appears to be statistically significant, displacement:year, acceleration:origin and acceleration:year because they have p-value smaller than 0.05.
- Question (f)
lm_model_squ <- lm(mpg ~ . + I(horsepower^2), data = auto)
lm_model_squ %>% summary() %>% print_summary_lm()- Formula: mpg ~ . + I(horsepower^2)
- Residuals
- Coefficients
- Residual standard error: 3.001 on 383 degrees of freedom.
- Multiple \(R^2\): 0.855.
- Adjusted \(R^2\): 0.852.
- F-statistic: 282.813 on 8 and 383, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 392 | 20.55 | 0 | 8.82 | -8.55 | -4.62 | -3.6 | -1.73 | -0.22 | 1.59 | 3.22 | 5.26 | 12 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 1.32366 | 4.62477 | 0.28621 | 0.77487184 |
| cylinders | 0.34891 | 0.30483 | 1.14459 | 0.25309407 |
| displacement | -0.00756 | 0.00737 | -1.02598 | 0.30554979 |
| horsepower | -0.31946 | 0.03434 | -9.30168 | < 2.22e-16 |
| weight | -0.00327 | 0.00068 | -4.82000 | 2.0735e-06 |
| acceleration | -0.33060 | 0.09918 | -3.33315 | 0.00094235 |
| year | 0.73534 | 0.04599 | 15.98852 | < 2.22e-16 |
| origin | 1.01441 | 0.25455 | 3.98505 | 8.0778e-05 |
| I(horsepower^2) | 0.00101 | 0.00011 | 9.44884 | < 2.22e-16 |
If we add the square transformation of the horsepower variable to the model, the model seems to be significative (the p-value of the F-statistic is still very low). The RSE is smaller for this model than for the linear model, however, it is still larger than the one of the model with all the interactions.
3.2.3 Exercise 10.
This exercise is about fitting a multiple linear model to the Carseats dataset. It contains 400 observations of 11 variables about sales of child car seats at different stores. For a description of the variables, please refer to R by typing help(Carseats) after loading the package ISLR.
- Question (a)
lm_model <- lm(Sales ~ Price + Urban + US, data = carseats)
lm_model %>% summary() %>% print_summary_lm()- Formula: Sales ~ Price + Urban + US
- Residuals
- Coefficients
- Residual standard error: 2.472 on 396 degrees of freedom.
- Multiple \(R^2\): 0.239.
- Adjusted \(R^2\): 0.234.
- F-statistic: 41.519 on 3 and 396, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 400 | 13.98 | 0 | 6.07 | -6.92 | -3.93 | -3.19 | -1.62 | -0.06 | 1.58 | 3.18 | 4.24 | 7.06 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 13.04347 | 0.65101 | 20.03567 | < 2.22e-16 |
| Price | -0.05446 | 0.00524 | -10.38923 | < 2.22e-16 |
| UrbanYes | -0.02192 | 0.27165 | -0.08068 | 0.93574 |
| USYes | 1.20057 | 0.25904 | 4.63467 | 4.8602e-06 |
- Question (b)
The variable Price seems to be very significative (p-value very close to 0) and its coefficient is negative (-0.0544588). So, a $100 increase in price company charges for car seats is associated with an average decrease in sales by around 5446 units. The p-value of the coefficient for the dummy variable UrbanYes is very close to 1. So, this indicates that there is no statistical evidence of a difference in unit sales (in thousands) of child car seats between the stores that are in urban or rural location. Finally, the variable USYes is also significative and its coefficient is positive (1.2005727). So, if the store is in the US will increase the sales by around 1201 units.
- Question (c)
The fitted model is:
\[ y_i = \beta_0 + \beta_1x_{1, i} + \beta_2x_{2, i} + \beta_3x_{3, i} + \epsilon_i\]
where
\(y_i\) represents the Sales (Unit sales in thousands at each location);
\(x_{1, i}\) represents the Price (Price company charges for seats at each site);
\(x_{2, i} = 1\) if the store is in an urban location, \(0\) is the store is in an rural location (UrbanYes);
\(x_{3, i} = 1\) if the store is in the US, \(0\) if not (USYes).
Question (d)
We can reject the null hypothesis for the variable Price and USYes (cf. question (b)).
- Question (e)
- Formula: Sales ~ Price + US
- Residuals
- Coefficients
- Residual standard error: 2.469 on 397 degrees of freedom.
- Multiple \(R^2\): 0.239.
- Adjusted \(R^2\): 0.235.
- F-statistic: 62.431 on 2 and 397, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 400 | 13.98 | 0 | 6.07 | -6.93 | -3.94 | -3.17 | -1.63 | -0.06 | 1.58 | 3.17 | 4.23 | 7.05 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 13.03079 | 0.63098 | 20.65179 | < 2.22e-16 |
| Price | -0.05448 | 0.00523 | -10.41612 | < 2.22e-16 |
| USYes | 1.19964 | 0.25846 | 4.64148 | 4.7072e-06 |
- Question (f)
The two models fit equally well on the data, they have the same \(R^2\) (this is another argument for dropping the variable Urban). However, we can consider that the second model is better because it uses less features.
- Question (g)
| 2.5 % | 97.5 % | |
|---|---|---|
| (Intercept) | 11.7903202 | 14.2712653 |
| Price | -0.0647598 | -0.0441954 |
| USYes | 0.6915196 | 1.7077663 |
- Question (h)
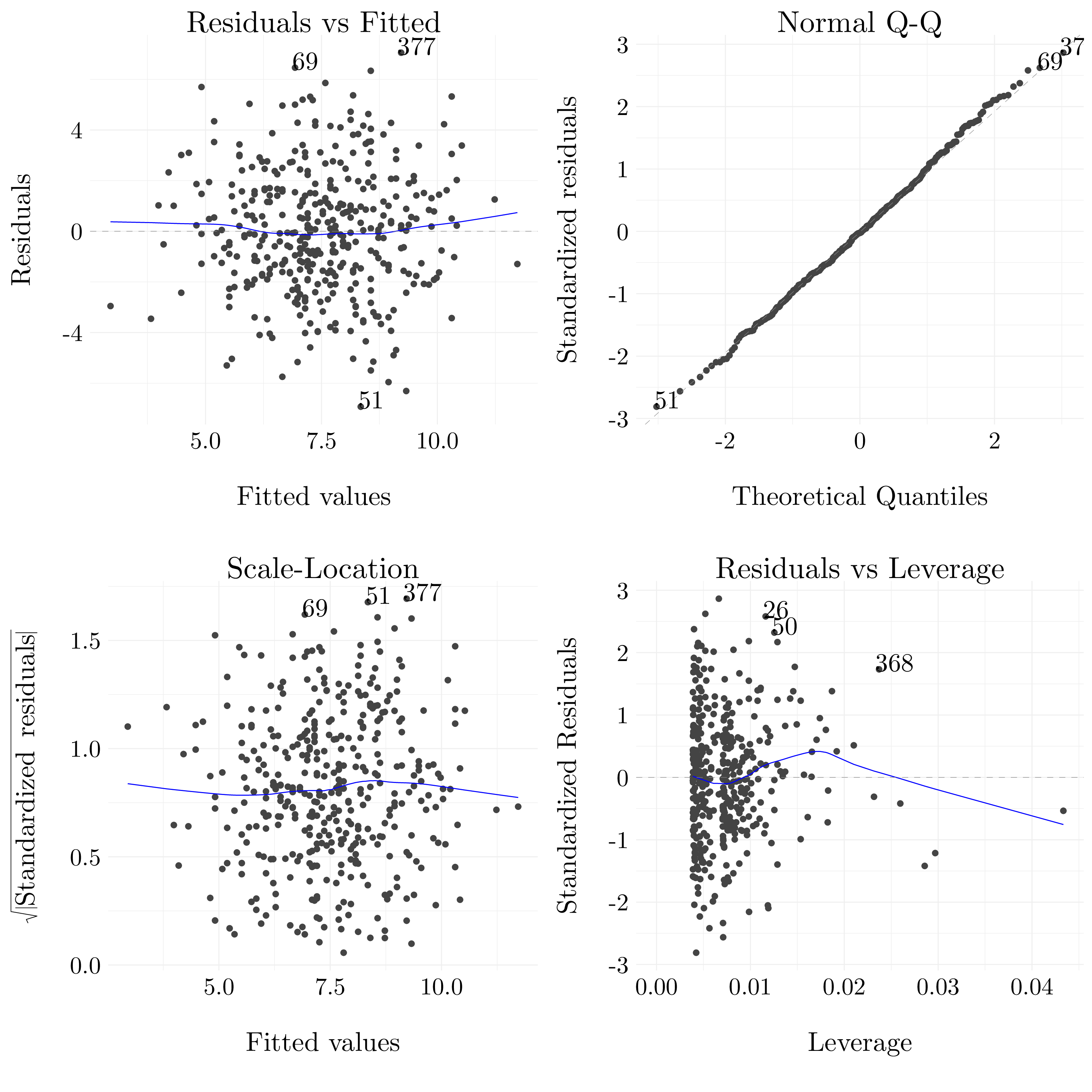
Figure 3.6: Diagnotistic plots of the multiple least square regression fit.
After looking at the different diagnostic plots, there is no particular evidence of outliers or high leverage observations in the model. However, the linear model may not be the better model for this data.
3.2.4 Exercise 11.
This exercise is about the t-statistic on models without intercept. For that, we will generate some data with the following “very” simple model:
\[y = 2x + \epsilon \quad\text{where}\quad \epsilon \sim \mathcal{N}(0,1).\]
- Question (a)
- Formula: y ~ x + 0
- Residuals
- Coefficients
- Residual standard error: 0.908 on 99 degrees of freedom.
- Multiple \(R^2\): 0.844.
- Adjusted \(R^2\): 0.842.
- F-statistic: 534.125 on 1 and 99, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 100 | 4.75 | -0.09 | 0.82 | -1.98 | -1.49 | -1.3 | -0.59 | -0.07 | 0.45 | 1.13 | 1.4 | 2.77 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| x | 2.02449 | 0.0876 | 23.11114 | < 2.22e-16 |
The p-value associated with the null hypothesis \(\beta = 0\) is very close to 0, so there is a strong evidence that the coefficient is statistically different from 0. The estimation of \(\beta\) is 2.0244855 which is very close to the true value.
- Question (b)
- Formula: x ~ y + 0
- Residuals
- Coefficients
- Residual standard error: 0.412 on 99 degrees of freedom.
- Multiple \(R^2\): 0.844.
- Adjusted \(R^2\): 0.842.
- F-statistic: 534.125 on 1 and 99, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 100 | 2.4 | 0.04 | 0.17 | -1.57 | -0.6 | -0.49 | -0.21 | 0.07 | 0.32 | 0.55 | 0.66 | 0.83 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| y | 0.41671 | 0.01803 | 23.11114 | < 2.22e-16 |
The value of the t-statistic is the same than for the previous model. So, we can reject the null hypothesis and the estimation of \(\beta\) is, as before, quite close to the true value.
- Question (c)
We can write the model from the question (a) as \(Y= \beta_1X + \epsilon\) and the one from the question (b) as \(X = \beta_2Y + \epsilon\). The least square estimation of the parameters leads to \(\widehat{\beta}_1 = (X^\top X)^{-1}X^\top Y\) and \(\widehat{\beta}_2 = (Y^\top Y)^{-1}Y^\top X\). Moreover, we have that \(X^\top Y = Y^\top X\). So, we have that:
\[\widehat{\beta}_1 = (X^\top X)^{-1}X^\top Y = Y^\top X(X^\top X)^{-1} = (Y^\top Y)\widehat{\beta}_2(X^\top X)^{-1}.\]
And finally, the relationship between \(\widehat{\beta}_1\) and \(\widehat{\beta}_2\) is:
\[\frac{\widehat{\beta}_1}{\widehat{\beta}_2} = (Y^\top Y)(X^\top X)^{-1},\]
which can be reduce to \(\frac{Var(Y)}{Var(X)}\) in the univariate case.
- Question (d)
Numerically, we found out that the t-statistic is 23.111142 which is coherent with the result given by the lm funtion.
Algebraically, the derivations are pretty straightforward: \[\begin{align} \frac{\widehat{\beta}}{SE(\widehat{\beta})} &= \frac{\sum x_iy_i}{\sum x_i^2} \sqrt{\frac{(n-1)\sum x_i^2}{\sum (y_i - x_i\widehat{\beta})^2}} \\ &= \frac{\sqrt{n-1}\sum x_iy_i}{\sqrt{x_i^2}\sqrt{\sum y_i^2 - 2\frac{\sum x_iy_i}{\sum x_i^2}\sum x_iy_i + \left(\frac{\sum x_iy_i}{\sum x_i^2}\right)^2\sum x_i^2}} \\ &= \frac{\sqrt{n-1}\sum x_iy_i}{\sqrt{x_i^2}\sqrt{\sum y_i^2 - 2\frac{\left(\sum x_iy_i\right)^2}{\sum x_i^2} + \left(\frac{\sum x_iy_i}{\sum x_i^2}\right)^2\sum x_i^2}} \\ &= \frac{\sqrt{n-1}\sum x_iy_i}{\sqrt{\sum x_i^2\sum y_i^2 - 2\left(\sum x_iy_i\right)^2 + \left(\sum x_iy_i\right)^2}} \\ &= \frac{\sqrt{n-1}\sum x_iy_i}{\sqrt{\sum x_i^2\sum y_i^2 - \left(\sum x_iy_i\right)^2}} \end{align}\]
- Question (e)
We can exchange \(X\) and \(Y\) in the formula of the t-statistic given in (d) without changing the results (which is the t-statistic). So, the t-statistic for the regression of \(Y\) onto \(X\) is the same as the t-statistic for the regression of \(X\) onto \(Y\).
- Question (f)
- Formula: y ~ x
- Residuals
- Coefficients
- Residual standard error: 0.908 on 98 degrees of freedom.
- Multiple \(R^2\): 0.845.
- Adjusted \(R^2\): 0.844.
- F-statistic: 534.715 on 1 and 98, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 100 | 4.75 | 0 | 0.82 | -1.89 | -1.4 | -1.21 | -0.51 | 0.01 | 0.54 | 1.21 | 1.49 | 2.86 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -0.08837 | 0.09088 | -0.97237 | 0.33326 |
| x | 2.02716 | 0.08767 | 23.12391 | < 2e-16 |
- Formula: x ~ y
- Residuals
- Coefficients
- Residual standard error: 0.412 on 98 degrees of freedom.
- Multiple \(R^2\): 0.845.
- Adjusted \(R^2\): 0.844.
- F-statistic: 534.715 on 1 and 98, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 100 | 2.4 | 0 | 0.17 | -1.61 | -0.64 | -0.53 | -0.25 | 0.03 | 0.27 | 0.51 | 0.62 | 0.79 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 0.04188 | 0.04119 | 1.01655 | 0.31187 |
| y | 0.41689 | 0.01803 | 23.12391 | < 2e-16 |
Considering the two tables, we can argue that the t-statistic for \(H_0 : \beta_1 = 0\) is the same for both regressions.
3.2.5 Exercise 12.
This exercise involves simple linear regression without an intercept.
- Question (a)
If we regress \(Y\) onto \(X\) without an intercept, we found that: \(\widehat{\beta}_1 = \sum x_iy_i / \sum x_i^2\).
If we regress \(X\) onto \(Y\) without an intercept, we found that: \(\widehat{\beta}_2 = \sum x_iy_i / \sum y_i^2\).
So, for \(\widehat{\beta}_1\) to be equal to \(\widehat{\beta}_2\), we should have \(\sum x_i^2 = \sum y_i^2\).
First, assume that \(\mathbb{E}(X) = \mathbb{E}(Y)\). So, \(\widehat{\beta}_1 = \widehat{\beta}_2 \iff \text{Var}(X) = \text{Var}(Y)\). If there is a linear relationship between \(X\) and \(Y\), it should exists \(a \in \mathbb{R}\) such that \(Y = aX\). And then \[\begin{align} \text{Var}(X) = \text{Var}(Y) &\iff \text{Var}(X) = \text{Var}(aX) \\ &\iff \text{Var}(X) = a^2\text{Var}(X) \\ &\iff a = 1 \text{ or } a = -1. \end{align}\]
Second, remove the assumption. If \(\sum x_i^2 = \sum y_i^2\), then
\[\text{Var}(X) + \mathbb{E}(X)^2 = \text{Var}(Y) + \mathbb{E}(Y)^2.\]
Again, if we assume linear relationship between \(X\) and \(Y\), it should exists \(a \in \mathbb{R}\) such that \(Y = aX\). And then \[\begin{align} \text{Var}(X) + \mathbb{E}(X)^2 = \text{Var}(Y) + \mathbb{E}(Y)^2 &\iff \text{Var}(X) + \mathbb{E}(X)^2 = a^2\left(\text{Var}(X) + \mathbb{E}(X)^2\right)\\ &\iff a = 1 \text{ or } a = -1. \end{align}\]
Finally, if we do not assume a particular relationship between \(X\) and \(Y\), we can simulate two random variables that appears to be i.i.d. but if we regress one on each other, we found out the same coefficients estimate (see question (c)).
- Question (b)
See exercise 11.
- Question (c)
- Formula: y ~ x + 0
- Residuals
- Coefficients
- Residual standard error: 2.261 on 9999 degrees of freedom.
- Multiple \(R^2\): 0.364.
- Adjusted \(R^2\): 0.364.
- F-statistic: 5725.596 on 1 and 9999, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 10000 | 16.3 | 1.25 | 3.55 | -6.02 | -1.89 | -1.13 | -0.01 | 1.25 | 2.52 | 3.64 | 4.34 | 10.27 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| x | 0.60567 | 0.008 | 75.66767 | < 2.22e-16 |
- Formula: x ~ y + 0
- Residuals
- Coefficients
- Residual standard error: 2.252 on 9999 degrees of freedom.
- Multiple \(R^2\): 0.364.
- Adjusted \(R^2\): 0.364.
- F-statistic: 5725.596 on 1 and 9999, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 10000 | 17.97 | 0.51 | 4.81 | -8.95 | -3.12 | -2.32 | -0.96 | 0.53 | 1.96 | 3.3 | 4.15 | 9.02 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| y | 0.60118 | 0.00795 | 75.66767 | < 2.22e-16 |
3.2.6 Exercise 13.
- Question (a)
- Question (b)
- Question (c)
The length of the vector y is 100 (same as x and eps). The true value of \(\beta_0\) is -1 and the one of \(\beta_1\) is 0.5.
- Question (d)

Figure 3.7: Scatterplot of y against x.
- Question (e)
- Formula: y ~ x
- Residuals
- Coefficients
- Residual standard error: 0.454 on 98 degrees of freedom.
- Multiple \(R^2\): 0.583.
- Adjusted \(R^2\): 0.579.
- F-statistic: 137.285 on 1 and 98, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 100 | 2.38 | 0 | 0.2 | -0.94 | -0.7 | -0.61 | -0.25 | 0.01 | 0.27 | 0.61 | 0.74 | 1.43 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -1.04418 | 0.04544 | -22.97996 | < 2.22e-16 |
| x | 0.51358 | 0.04383 | 11.71686 | < 2.22e-16 |
The estimation of the coefficients are very closed to the true ones, and both are statistically significative. However, the \(R^2\) is quite poor (around 0.5), which seems to mean that the model does not explain the data very well.
- Question (f)
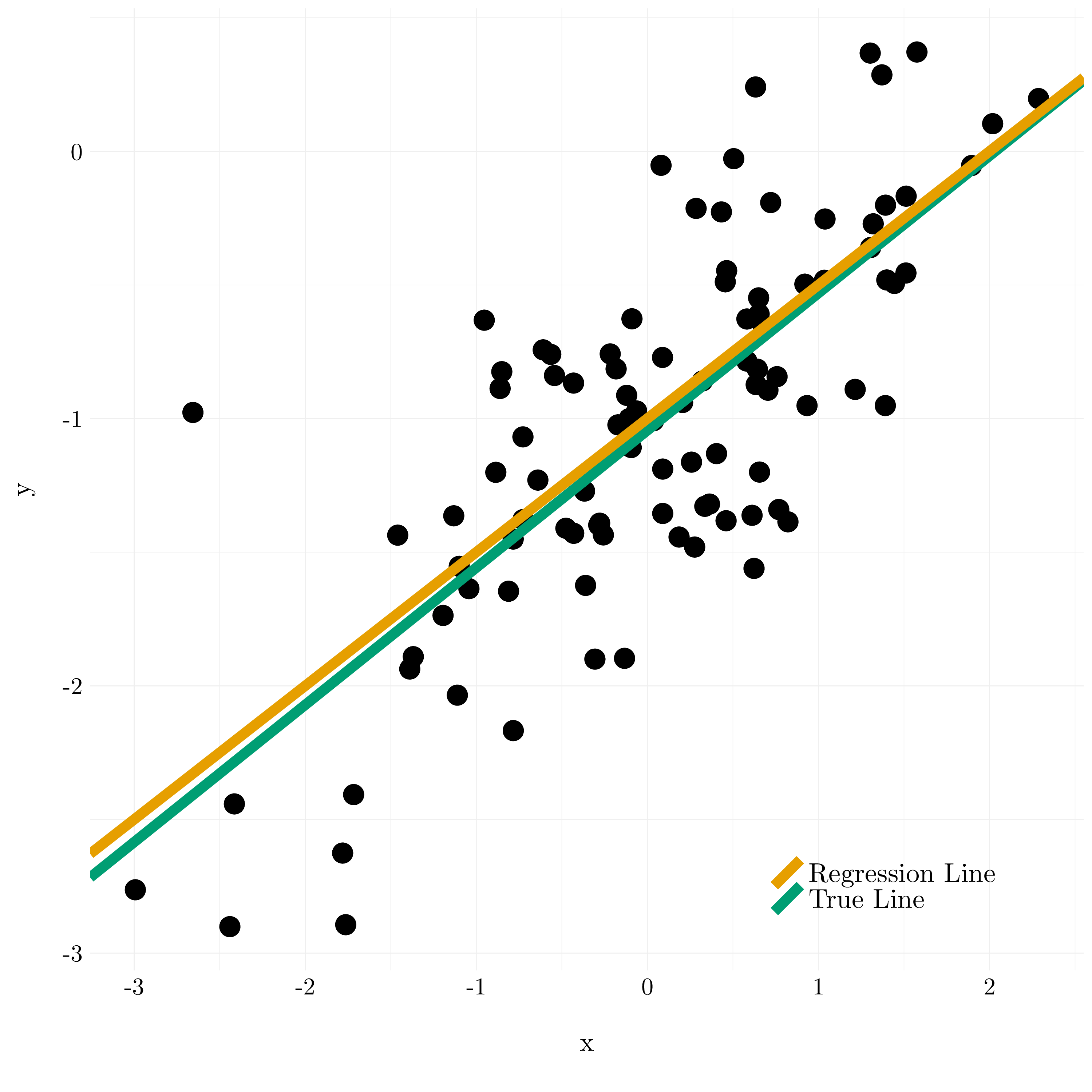
Figure 3.8: Results of the linear regression of y against x.
- Question (g)
- Formula: y ~ x + I(x^2)
- Residuals
- Coefficients
- Residual standard error: 0.456 on 97 degrees of freedom.
- Multiple \(R^2\): 0.584.
- Adjusted \(R^2\): 0.575.
- F-statistic: 67.959 on 2 and 97, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 100 | 2.36 | 0 | 0.2 | -0.95 | -0.7 | -0.62 | -0.25 | 0 | 0.27 | 0.6 | 0.74 | 1.41 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -1.04812 | 0.05627 | -18.62702 | < 2e-16 |
| x | 0.51513 | 0.04591 | 11.21951 | < 2e-16 |
| I(x^2) | 0.00362 | 0.03020 | 0.11990 | 0.90481 |
Based on the table, there is no evidence that the quadratic term improves the model fit. In particular, the p-value for the coefficient of the quadratic term is very high, and thus this term is not statistically significative. Moreover, the \(R^2\) does not increase a lot when we add the quadratic term.
- Question (h), (i) and (j)
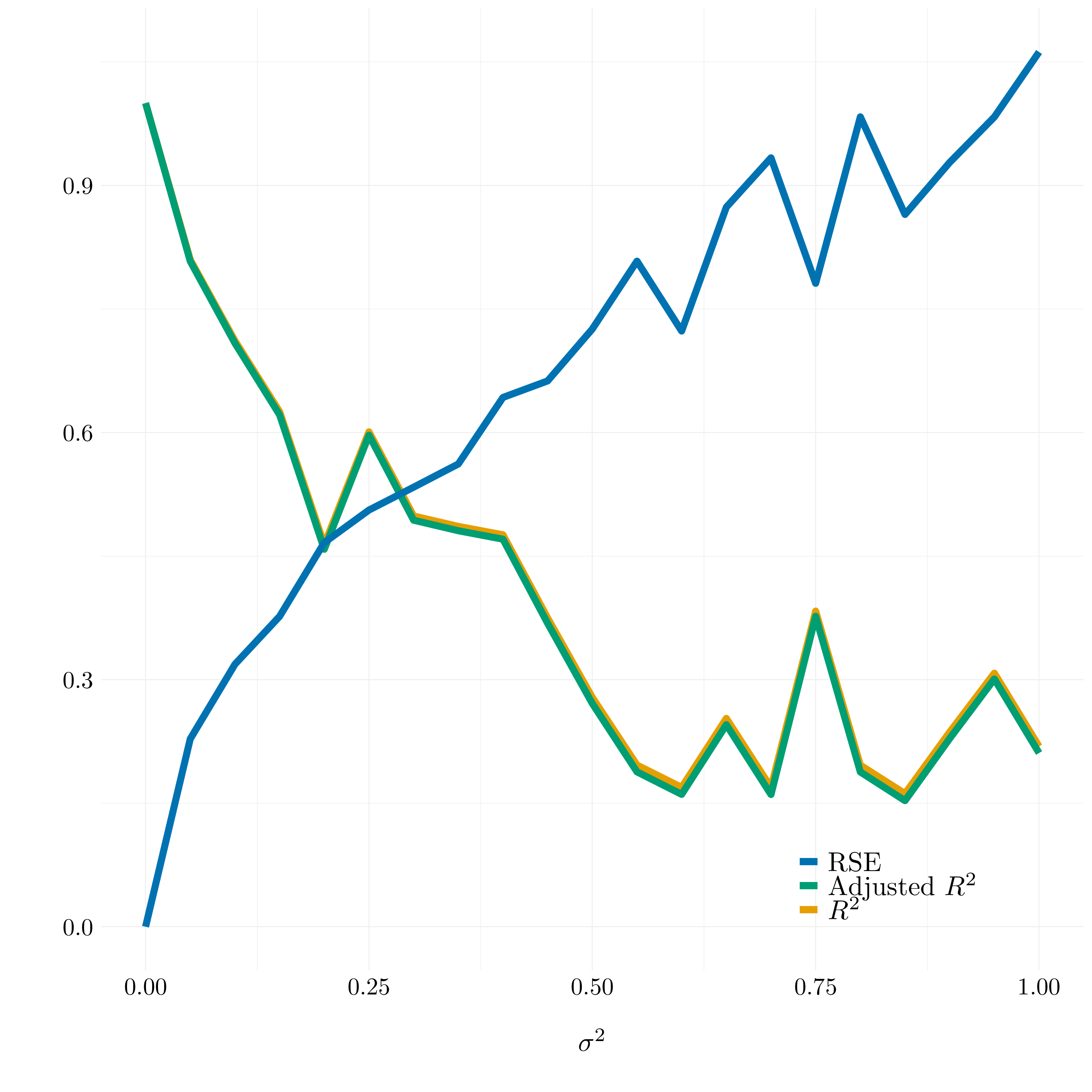
Figure 3.9: Different results for the \(R^2\), the adjusted \(R^2\) and the RSE
As we see on the graph, the \(R^2\) and the adjusted \(R^2\) will decresase when the variance of the noise increase, and conversely for the residual standard errors. This phenomena could be predicted because the more noise we add the less we can recover the true underlying function.
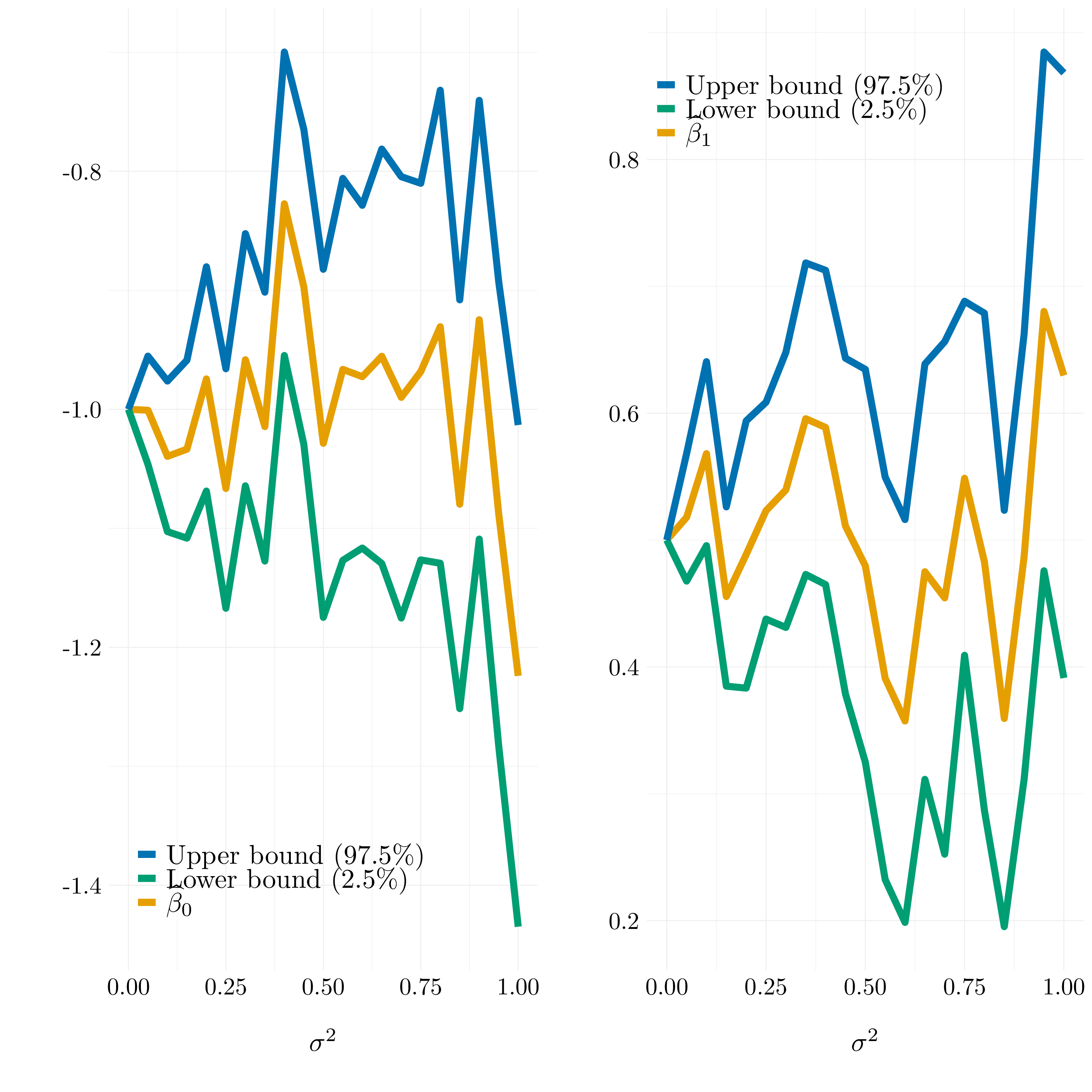
Figure 3.10: Confidence intervals for the estimated coefficients
The confidence intervals for the two coefficients show the same phenomena than the \(R^2\), the adjusted \(R^2\) and the residual standard errors. The more the variance of the noise increases, the more difficult it is to estimate the coefficients, and to have a good confidence interval on it. In fact, the confidence interval is larger for large noise and the coefficient can be further from the true one.
3.2.7 Exercise 14.
This exercise is about the problem of collinearity in the features.
- Question (a)
The linear model is the following:
\[ Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \epsilon \text{ where } \beta_0 = 2,~ \beta_1 = 2,~ \beta_2 = 0.3 \text{ and } \epsilon \sim \mathcal{N}(0, 1).\]
- Question (b)
ggplot() +
geom_point(aes(x = x1, y = x2), size = 6) +
annotate("text", x = 0.1, y = 0.6, label = paste('Correlation:', round(cor(x1, x2), 2)), size = 8, col = 'red') +
xlab("$X_1$") +
ylab("$X_2$") +
theme_custom()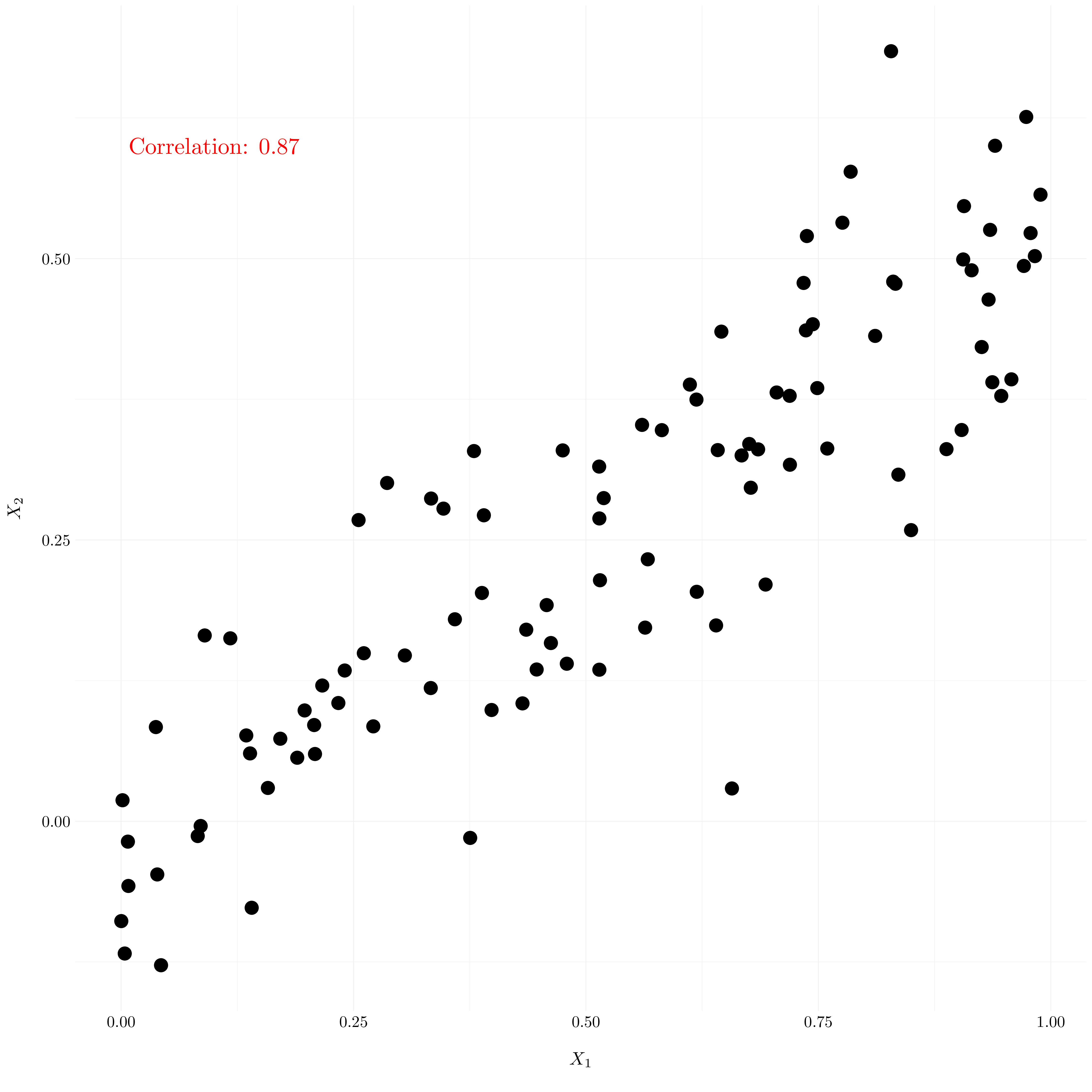
Figure 3.11: Scatterplot of \(X_1\) against \(X_2\).
- Question (c)
- Formula: y ~ x1 + x2
- Residuals
- Coefficients
- Residual standard error: 0.941 on 97 degrees of freedom.
- Multiple \(R^2\): 0.32.
- Adjusted \(R^2\): 0.306.
- F-statistic: 22.802 on 2 and 97, p-value: 7.64e-09.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 100 | 4.18 | 0 | 0.87 | -2.1 | -1.38 | -1.26 | -0.66 | -0.03 | 0.65 | 1.27 | 1.41 | 2.08 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 2.04617 | 0.19102 | 10.71198 | < 2e-16 |
| x1 | 1.55979 | 0.63982 | 2.43787 | 0.016595 |
| x2 | 0.98083 | 1.02652 | 0.95549 | 0.341706 |
The value of \(\widehat{\beta}_0\) is 2.0461711 which is quite close to the true value of \(\beta_0\). However, both the value of \(\widehat{\beta}_1\) (1.5597949) and \(\widehat{\beta}_2\) (0.9808272) appear to be quite far from their true value even if we obviously know that the true relationship between \(Y\), \(X_1\) and \(X_2\) is linear. Thanks to the p-value, we can reject the null hypothesis only for \(\beta_1\), and so \(\beta_2\) does not seem to be statistically significant. Finaly, the \(R^2\) is not very good.
- Question (d)
- Formula: y ~ x1
- Residuals
- Coefficients
- Residual standard error: 0.94 on 98 degrees of freedom.
- Multiple \(R^2\): 0.313.
- Adjusted \(R^2\): 0.306.
- F-statistic: 44.731 on 1 and 98, p-value: 1.4e-09.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 100 | 4.11 | 0 | 0.87 | -1.97 | -1.42 | -1.22 | -0.69 | -0.02 | 0.56 | 1.24 | 1.59 | 2.14 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 2.02128 | 0.18915 | 10.68623 | < 2.22e-16 |
| x1 | 2.09295 | 0.31293 | 6.68812 | 1.4022e-09 |
The estimated coefficients are both statistically significant. The residual standard error and the \(R^2\) are the same than for the model with \(X_2\). We can reject the null hypothesis.
- Question (e)
- Formula: y ~ x2
- Residuals
- Coefficients
- Residual standard error: 0.964 on 98 degrees of freedom.
- Multiple \(R^2\): 0.278.
- Adjusted \(R^2\): 0.271.
- F-statistic: 37.756 on 1 and 98, p-value: 1.73e-08.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 100 | 4.72 | 0 | 0.92 | -2.45 | -1.46 | -1.23 | -0.7 | -0.06 | 0.66 | 1.23 | 1.58 | 2.27 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 2.29744 | 0.16483 | 13.93816 | < 2.22e-16 |
| x2 | 3.16330 | 0.51481 | 6.14463 | 1.7269e-08 |
The estimated coefficients are both statistically significant. The residual standard error and the \(R^2\) are a little smaller than for the model with \(X_1\). We can reject the null hypothesis.
- Question (f)
At a first sight, the different results can contradict each other, because it result to very different coefficients estimation and statistical significance. But, if we look at the true model, we see that \(X_1\) and \(X_2\) are very correlated. So, they explained the same variance in the data. In the complete model, they more or less share the explication of the variance but as they can explain the same amount of variance, the model with only \(X_1\) or \(X_2\) will lead to the same results. Another problem that can arrive in this case is that the matrix \(X^\prime X\) may not be invertible.
- Question (g)
- Question (h)
- Formula: y ~ x1 + x2
- Residuals
- Coefficients
- Residual standard error: 0.964 on 98 degrees of freedom.
- Multiple \(R^2\): 0.323.
- Adjusted \(R^2\): 0.309.
- F-statistic: 23.327 on 2 and 98, p-value: 5.18e-09.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 101 | 4.45 | 0 | 0.91 | -2.34 | -1.41 | -1.26 | -0.71 | -0.03 | 0.72 | 1.27 | 1.69 | 2.11 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 2.14668 | 0.19109 | 11.23357 | < 2.22e-16 |
| x1 | 0.61282 | 0.51998 | 1.17854 | 0.2414353 |
| x2 | 2.57296 | 0.80975 | 3.17746 | 0.0019877 |
The new point changes the significance of the coefficient for this model. Now, \(\beta_1\) is not significant anymore, while \(\beta_2\) is. The other values do not seem to change. We do not have an increasing of the RSE, so the new point is not an outlier. The leverage statistic of the new point is 0.1 while the average leverage is 0.03. So, the new point is a high-leverage point.
- Formula: y ~ x1
- Residuals
- Coefficients
- Residual standard error: 1.007 on 99 degrees of freedom.
- Multiple \(R^2\): 0.253.
- Adjusted \(R^2\): 0.245.
- F-statistic: 33.481 on 1 and 99, p-value: 8.45e-08.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 101 | 5.7 | 0 | 1 | -2.04 | -1.48 | -1.26 | -0.73 | -0.08 | 0.54 | 1.25 | 1.73 | 3.66 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 2.14814 | 0.19968 | 10.75791 | < 2.22e-16 |
| x1 | 1.92083 | 0.33196 | 5.78629 | 8.4547e-08 |
The new point changes a lot the RSE and the \(R^2\). So, it should be consider as an outlier in this case. The leverage statistic of the new point is 0.03 while the average leverage is 0.02. So, the new point is a high-leverage point.
- Formula: y ~ x2
- Residuals
- Coefficients
- Residual standard error: 0.966 on 99 degrees of freedom.
- Multiple \(R^2\): 0.313.
- Adjusted \(R^2\): 0.306.
- F-statistic: 45.088 on 1 and 99, p-value: 1.2e-09.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 101 | 4.68 | 0 | 0.92 | -2.47 | -1.47 | -1.2 | -0.68 | -0.05 | 0.68 | 1.23 | 1.55 | 2.22 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 2.26526 | 0.16278 | 13.91614 | < 2.22e-16 |
| x2 | 3.32847 | 0.49570 | 6.71473 | 1.1974e-09 |
The new point improve this model. So, this point is not an outlier. The leverage statistic of the new point is 0.02 while the average leverage is 0.02. So, the new point is not a high-leverage point.
3.2.8 Exercise 15.
This exercise is about the Boston dataset. We would like to predict per capita crime rate based on the other features. It contains 506 observations of 14 variables of suburbs in Boston. For a description of the variables, please refer to R by typing help(Boston) after loading the pacakge MASS.
boston <- as_tibble(Boston)
variable <- c("zn", "indus", "chas", "nox", "rm", "age", "dis", "rad", "tax", "ptratio", "black", "lstat", "medv")- Question (a)
lm_list <- vector("list", length = length(boston)-1)
for(i in seq(1, length(boston)-1)){
name <- variable[i]
lm_list[[i]] <- lm(boston$crim ~ boston[[name]])
}
names(lm_list) <- variableVariable zn
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 8.435 on 504 degrees of freedom.
- Multiple \(R^2\): 0.04.
- Adjusted \(R^2\): 0.038.
- F-statistic: 21.103 on 1 and 504, p-value: 5.51e-06.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 88.95 | 0 | 71.01 | -4.43 | -4.4 | -4.37 | -4.22 | -2.62 | 1.25 | 6.3 | 11.34 | 84.52 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 4.45369 | 0.41722 | 10.67475 | < 2.22e-16 |
| boston[[name]] | -0.07393 | 0.01609 | -4.59378 | 5.5065e-06 |
Variable indus
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 7.866 on 504 degrees of freedom.
- Multiple \(R^2\): 0.165.
- Adjusted \(R^2\): 0.164.
- F-statistic: 99.817 on 1 and 504, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 93.78 | 0 | 61.76 | -11.97 | -7.79 | -5.54 | -2.7 | -0.74 | 0.71 | 3.59 | 8.63 | 81.81 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -2.06374 | 0.66723 | -3.09301 | 0.0020913 |
| boston[[name]] | 0.50978 | 0.05102 | 9.99085 | < 2.22e-16 |
Variable chas
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 8.597 on 504 degrees of freedom.
- Multiple \(R^2\): 0.003.
- Adjusted \(R^2\): 0.001.
- F-statistic: 1.579 on 1 and 504, p-value: 0.209.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 88.97 | 0 | 73.76 | -3.74 | -3.72 | -3.71 | -3.66 | -3.44 | 0.02 | 7.11 | 12.04 | 85.23 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 3.74445 | 0.39611 | 9.45302 | < 2e-16 |
| boston[[name]] | -1.89278 | 1.50612 | -1.25673 | 0.20943 |
Variable nox
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 7.81 on 504 degrees of freedom.
- Multiple \(R^2\): 0.177.
- Adjusted \(R^2\): 0.176.
- F-statistic: 108.555 on 1 and 504, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 94.1 | 0 | 60.87 | -12.37 | -5.88 | -4.96 | -2.74 | -0.97 | 0.56 | 3.41 | 9.41 | 81.73 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -13.71988 | 1.69948 | -8.07299 | 5.0768e-15 |
| boston[[name]] | 31.24853 | 2.99919 | 10.41899 | < 2.22e-16 |
Variable rm
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 8.401 on 504 degrees of freedom.
- Multiple \(R^2\): 0.048.
- Adjusted \(R^2\): 0.046.
- F-statistic: 25.45 on 1 and 504, p-value: 6.35e-07.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 93.8 | 0 | 70.43 | -6.6 | -4.98 | -4.64 | -3.95 | -2.65 | 0.99 | 6.92 | 11.26 | 87.2 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 20.48180 | 3.36447 | 6.08767 | 2.2720e-09 |
| boston[[name]] | -2.68405 | 0.53204 | -5.04482 | 6.3467e-07 |
Variable age
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 8.057 on 504 degrees of freedom.
- Multiple \(R^2\): 0.124.
- Adjusted \(R^2\): 0.123.
- F-statistic: 71.619 on 1 and 504, p-value: 2.85e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 89.64 | 0 | 64.78 | -6.79 | -6.16 | -5.6 | -4.26 | -1.23 | 1.53 | 4.65 | 9.91 | 82.85 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -3.77791 | 0.94398 | -4.00208 | 7.2217e-05 |
| boston[[name]] | 0.10779 | 0.01274 | 8.46282 | 2.8549e-16 |
Variable dis
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 7.965 on 504 degrees of freedom.
- Multiple \(R^2\): 0.144.
- Adjusted \(R^2\): 0.142.
- F-statistic: 84.888 on 1 and 504, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 88.38 | 0 | 63.32 | -6.71 | -5.9 | -5.44 | -4.13 | -1.53 | 1.52 | 4.9 | 9.32 | 81.67 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 9.49926 | 0.73040 | 13.00561 | < 2.22e-16 |
| boston[[name]] | -1.55090 | 0.16833 | -9.21346 | < 2.22e-16 |
Variable rad
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 6.718 on 504 degrees of freedom.
- Multiple \(R^2\): 0.391.
- Adjusted \(R^2\): 0.39.
- F-statistic: 323.935 on 1 and 504, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 86.6 | 0 | 45.04 | -10.16 | -7.6 | -5.08 | -1.38 | -0.14 | 0.66 | 1.7 | 3.31 | 76.43 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -2.28716 | 0.44348 | -5.15735 | 3.6058e-07 |
| boston[[name]] | 0.61791 | 0.03433 | 17.99820 | < 2.22e-16 |
Variable tax
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 6.997 on 504 degrees of freedom.
- Multiple \(R^2\): 0.34.
- Adjusted \(R^2\): 0.338.
- F-statistic: 259.19 on 1 and 504, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 90.21 | 0 | 48.86 | -12.51 | -6.59 | -4.52 | -2.74 | -0.19 | 1.07 | 2.81 | 4.51 | 77.7 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -8.52837 | 0.81581 | -10.45387 | < 2.22e-16 |
| boston[[name]] | 0.02974 | 0.00185 | 16.09939 | < 2.22e-16 |
Variable ptratio
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 8.24 on 504 degrees of freedom.
- Multiple \(R^2\): 0.084.
- Adjusted \(R^2\): 0.082.
- F-statistic: 46.259 on 1 and 504, p-value: 2.94e-11.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 91.01 | 0 | 67.77 | -7.65 | -6.22 | -5.57 | -3.99 | -1.91 | 1.82 | 5.13 | 10.17 | 83.35 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -17.64693 | 3.14727 | -5.60706 | 3.3953e-08 |
| boston[[name]] | 1.15198 | 0.16937 | 6.80143 | 2.9429e-11 |
Variable black
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 7.946 on 504 degrees of freedom.
- Multiple \(R^2\): 0.148.
- Adjusted \(R^2\): 0.147.
- F-statistic: 87.74 on 1 and 504, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 100.58 | 0 | 63.02 | -13.76 | -4.87 | -3 | -2.3 | -2.09 | -1.3 | 5.76 | 11.85 | 86.82 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 16.55353 | 1.42590 | 11.60916 | < 2.22e-16 |
| boston[[name]] | -0.03628 | 0.00387 | -9.36695 | < 2.22e-16 |
Variable lstat
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 7.664 on 504 degrees of freedom.
- Multiple \(R^2\): 0.208.
- Adjusted \(R^2\): 0.206.
- F-statistic: 132.035 on 1 and 504, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 96.79 | 0 | 58.63 | -13.93 | -6.75 | -5.38 | -2.82 | -0.66 | 1.08 | 3.91 | 8.14 | 82.86 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -3.33054 | 0.69376 | -4.80072 | 2.087e-06 |
| boston[[name]] | 0.54880 | 0.04776 | 11.49065 | < 2.22e-16 |
Variable medv
- Formula: boston$crim ~ boston[[name]]
- Residuals
- Coefficients
- Residual standard error: 7.934 on 504 degrees of freedom.
- Multiple \(R^2\): 0.151.
- Adjusted \(R^2\): 0.149.
- F-statistic: 89.486 on 1 and 504, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 90.03 | 0 | 62.83 | -9.07 | -5.47 | -4.9 | -4.02 | -2.34 | 1.3 | 6.4 | 11.43 | 80.96 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 11.79654 | 0.93419 | 12.62757 | < 2.22e-16 |
| boston[[name]] | -0.36316 | 0.03839 | -9.45971 | < 2.22e-16 |
If we look at the results of the different fitted linear model, we can see that almost every variable is statistically significative (except the variable chas). However, We can split up the other ones into three categories based on the \(R^2\). The variable with a large \(R^2\) (\(> 0.3\)) have a larger contribution to the variance explication (rad and tax). Then, there are variables with a moderate contribution to the variance: indus, nox, age, dis, black, lstat and medv (between \(0.1\) and \(0.2\)). Finally, some of them have a \(R^2\) very close to \(0\) (zn, rm and ptratio).
- Question (b)
- Formula: crim ~ .
- Residuals
- Coefficients
- Residual standard error: 6.439 on 492 degrees of freedom.
- Multiple \(R^2\): 0.454.
- Adjusted \(R^2\): 0.44.
- F-statistic: 31.47 on 13 and 492, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 84.97 | 0 | 40.4 | -9.92 | -6.37 | -4.51 | -2.12 | -0.35 | 1.02 | 2.49 | 4.66 | 75.05 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 17.03323 | 7.23490 | 2.35431 | 0.0189491 |
| zn | 0.04486 | 0.01873 | 2.39431 | 0.0170249 |
| indus | -0.06385 | 0.08341 | -0.76558 | 0.4442940 |
| chas | -0.74913 | 1.18015 | -0.63478 | 0.5258670 |
| nox | -10.31353 | 5.27554 | -1.95497 | 0.0511520 |
| rm | 0.43013 | 0.61283 | 0.70188 | 0.4830888 |
| age | 0.00145 | 0.01793 | 0.08098 | 0.9354878 |
| dis | -0.98718 | 0.28182 | -3.50289 | 0.0005022 |
| rad | 0.58821 | 0.08805 | 6.68045 | 6.4605e-11 |
| tax | -0.00378 | 0.00516 | -0.73319 | 0.4637927 |
| ptratio | -0.27108 | 0.18645 | -1.45390 | 0.1466113 |
| black | -0.00754 | 0.00367 | -2.05196 | 0.0407023 |
| lstat | 0.12621 | 0.07572 | 1.66671 | 0.0962084 |
| medv | -0.19889 | 0.06052 | -3.28652 | 0.0010868 |
The multiple linear regression appears to be quite good on these data. The model is significative and the \(R^2\) is better than the one for every univariate linear model. We can reject the null hypothesis for the features zn, dis, rad, black and medv. The significative variable are not the same than the one for the univariate models. This may be the result of some colinearity problems.
- Question (c)
coefs <- tibble(variable = names(lm$coefficients), beta_multi = lm$coefficients) %>% slice(-1)
coefs$beta_uni <- lm_list %>% map(~ .x$coefficients[-1]) %>% unlist()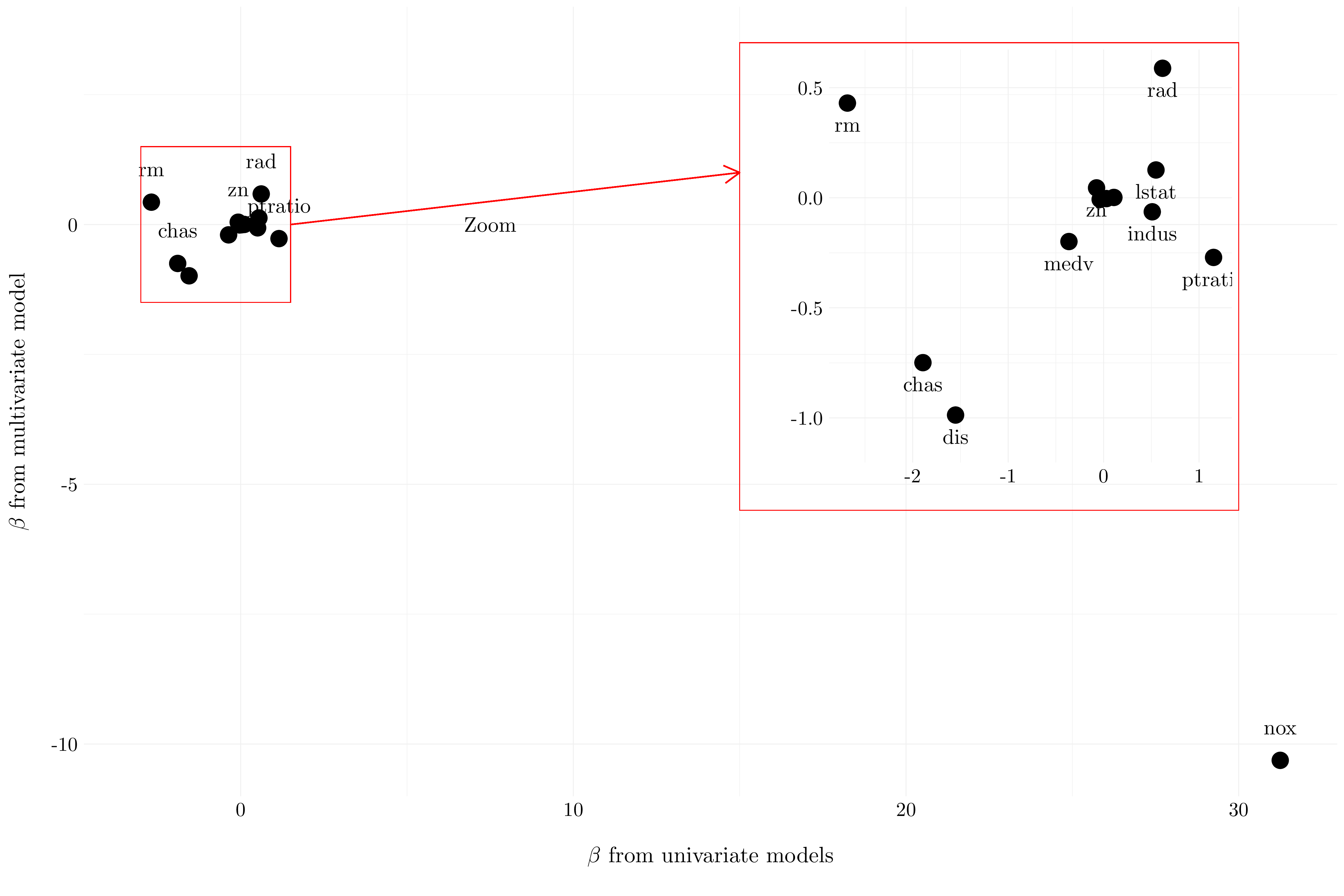
Figure 3.12: Plot of the coefficients from the univariate models against the multivariate model.
As we see, the estimated coefficients are very different if we fit a multivariate model or multiple univariate models.
- Question (d)
lm_list <- vector("list", length = length(boston)-1)
for(i in seq(1, length(boston)-1)){
name <- variable[i]
lm_list[[i]] <- lm(boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3))
}
names(lm_list) <- variableVariable zn
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 8.372 on 502 degrees of freedom.
- Multiple \(R^2\): 0.058.
- Adjusted \(R^2\): 0.053.
- F-statistic: 10.349 on 3 and 502, p-value: 1.28e-06.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 88.95 | 0 | 69.68 | -4.82 | -4.79 | -4.76 | -4.61 | -1.29 | 0.47 | 5.91 | 10.94 | 84.13 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 4.84605 | 0.43298 | 11.19220 | < 2.22e-16 |
| boston[[name]] | -0.33219 | 0.10981 | -3.02517 | 0.0026123 |
| I(boston[[name]]^2) | 0.00648 | 0.00386 | 1.67912 | 0.0937505 |
| I(boston[[name]]^3) | -0.00004 | 0.00003 | -1.20301 | 0.2295386 |
Variable indus
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 7.423 on 502 degrees of freedom.
- Multiple \(R^2\): 0.26.
- Adjusted \(R^2\): 0.255.
- F-statistic: 58.688 on 3 and 502, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 87.99 | 0 | 54.78 | -8.28 | -7.33 | -6.22 | -2.51 | 0.05 | 0.76 | 2.43 | 6.53 | 79.71 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 3.66257 | 1.57398 | 2.32694 | 0.020365 |
| boston[[name]] | -1.96521 | 0.48199 | -4.07729 | 5.2971e-05 |
| I(boston[[name]]^2) | 0.25194 | 0.03932 | 6.40701 | 3.4202e-10 |
| I(boston[[name]]^3) | -0.00698 | 0.00096 | -7.29205 | 1.1964e-12 |
Variable chas
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 8.597 on 504 degrees of freedom.
- Multiple \(R^2\): 0.003.
- Adjusted \(R^2\): 0.001.
- F-statistic: 1.579 on 1 and 504, p-value: 0.209.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 88.97 | 0 | 73.76 | -3.74 | -3.72 | -3.71 | -3.66 | -3.44 | 0.02 | 7.11 | 12.04 | 85.23 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 3.74445 | 0.39611 | 9.45302 | < 2e-16 |
| boston[[name]] | -1.89278 | 1.50612 | -1.25673 | 0.20943 |
Variable nox
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 7.234 on 502 degrees of freedom.
- Multiple \(R^2\): 0.297.
- Adjusted \(R^2\): 0.293.
- F-statistic: 70.687 on 3 and 502, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 87.41 | 0 | 52.01 | -9.11 | -7.35 | -6.16 | -2.07 | -0.25 | 0.74 | 1.92 | 7.88 | 78.3 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 233.0866 | 33.6431 | 6.92821 | 1.3119e-11 |
| boston[[name]] | -1279.3712 | 170.3975 | -7.50816 | 2.7584e-13 |
| I(boston[[name]]^2) | 2248.5440 | 279.8993 | 8.03340 | 6.8113e-15 |
| I(boston[[name]]^3) | -1245.7029 | 149.2816 | -8.34465 | 6.9611e-16 |
Variable rm
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 8.33 on 502 degrees of freedom.
- Multiple \(R^2\): 0.068.
- Adjusted \(R^2\): 0.062.
- F-statistic: 12.168 on 3 and 502, p-value: 1.07e-07.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 105.7 | 0 | 68.97 | -18.49 | -5.13 | -4.34 | -3.47 | -2.22 | -0.01 | 6.82 | 11.58 | 87.22 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 112.62460 | 64.51724 | 1.74565 | 0.081483 |
| boston[[name]] | -39.15014 | 31.31149 | -1.25034 | 0.211756 |
| I(boston[[name]]^2) | 4.55090 | 5.00986 | 0.90839 | 0.364109 |
| I(boston[[name]]^3) | -0.17448 | 0.26375 | -0.66153 | 0.508575 |
Variable age
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 7.84 on 502 degrees of freedom.
- Multiple \(R^2\): 0.174.
- Adjusted \(R^2\): 0.169.
- F-statistic: 35.306 on 3 and 502, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 92.6 | 0 | 61.1 | -9.76 | -7.8 | -6.42 | -2.67 | -0.52 | 0.02 | 4.38 | 8.77 | 82.84 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -2.54876 | 2.76914 | -0.92042 | 0.3577971 |
| boston[[name]] | 0.27365 | 0.18638 | 1.46826 | 0.1426608 |
| I(boston[[name]]^2) | -0.00723 | 0.00364 | -1.98779 | 0.0473773 |
| I(boston[[name]]^3) | 0.00006 | 0.00002 | 2.72373 | 0.0066799 |
Variable dis
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 7.331 on 502 degrees of freedom.
- Multiple \(R^2\): 0.278.
- Adjusted \(R^2\): 0.274.
- F-statistic: 64.374 on 3 and 502, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 87.14 | 0 | 53.43 | -10.76 | -8.45 | -6.51 | -2.59 | 0.03 | 1.27 | 3.41 | 6.72 | 76.38 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 30.04761 | 2.44587 | 12.28504 | < 2.22e-16 |
| boston[[name]] | -15.55435 | 1.73597 | -8.96005 | < 2.22e-16 |
| I(boston[[name]]^2) | 2.45207 | 0.34642 | 7.07833 | 4.9412e-12 |
| I(boston[[name]]^3) | -0.11860 | 0.02040 | -5.81354 | 1.0888e-08 |
Variable rad
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 6.682 on 502 degrees of freedom.
- Multiple \(R^2\): 0.4.
- Adjusted \(R^2\): 0.396.
- F-statistic: 111.573 on 3 and 502, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 86.6 | 0 | 44.39 | -10.38 | -7.81 | -5.29 | -0.41 | -0.27 | 0.18 | 1.55 | 3.11 | 76.22 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | -0.60554 | 2.05011 | -0.29537 | 0.76783 |
| boston[[name]] | 0.51274 | 1.04360 | 0.49132 | 0.62342 |
| I(boston[[name]]^2) | -0.07518 | 0.14854 | -0.50610 | 0.61301 |
| I(boston[[name]]^3) | 0.00321 | 0.00456 | 0.70311 | 0.48231 |
Variable tax
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 6.854 on 502 degrees of freedom.
- Multiple \(R^2\): 0.369.
- Adjusted \(R^2\): 0.365.
- F-statistic: 97.805 on 3 and 502, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 90.22 | 0 | 46.69 | -13.27 | -7.34 | -5.14 | -1.39 | 0.05 | 0.54 | 1.34 | 3.76 | 76.95 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 19.18358 | 11.79555 | 1.62634 | 0.10450 |
| boston[[name]] | -0.15331 | 0.09568 | -1.60235 | 0.10971 |
| I(boston[[name]]^2) | 0.00036 | 0.00024 | 1.48766 | 0.13747 |
| I(boston[[name]]^3) | 0.00000 | 0.00000 | -1.16679 | 0.24385 |
Variable ptratio
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 8.122 on 502 degrees of freedom.
- Multiple \(R^2\): 0.114.
- Adjusted \(R^2\): 0.108.
- F-statistic: 21.484 on 3 and 502, p-value: 4.17e-13.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 505 | 89.53 | 0 | 65.57 | -6.83 | -6.3 | -5.99 | -4.15 | -1.65 | 1.41 | 4.73 | 9.51 | 82.7 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 477.18405 | 156.79498 | 3.04336 | 0.0024621 |
| boston[[name]] | -82.36054 | 27.64394 | -2.97933 | 0.0030287 |
| I(boston[[name]]^2) | 4.63535 | 1.60832 | 2.88210 | 0.0041196 |
| I(boston[[name]]^3) | -0.08476 | 0.03090 | -2.74328 | 0.0063005 |
Variable black
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 7.955 on 502 degrees of freedom.
- Multiple \(R^2\): 0.15.
- Adjusted \(R^2\): 0.145.
- F-statistic: 29.492 on 3 and 502, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 99.89 | 0 | 62.9 | -13.1 | -4.32 | -2.99 | -2.34 | -2.13 | -1.44 | 5.87 | 11.82 | 86.79 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 18.26370 | 2.30490 | 7.92385 | 1.4971e-14 |
| boston[[name]] | -0.08356 | 0.05633 | -1.48343 | 0.13859 |
| I(boston[[name]]^2) | 0.00021 | 0.00030 | 0.71624 | 0.47418 |
| I(boston[[name]]^3) | 0.00000 | 0.00000 | -0.60777 | 0.54362 |
Variable lstat
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 7.629 on 502 degrees of freedom.
- Multiple \(R^2\): 0.218.
- Adjusted \(R^2\): 0.213.
- F-statistic: 46.629 on 3 and 502, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 98.59 | 0 | 57.86 | -15.23 | -6.58 | -4.93 | -2.15 | -0.49 | 0.07 | 4.03 | 8.3 | 83.35 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 1.20097 | 2.02865 | 0.59200 | 0.554115 |
| boston[[name]] | -0.44907 | 0.46489 | -0.96596 | 0.334530 |
| I(boston[[name]]^2) | 0.05578 | 0.03012 | 1.85218 | 0.064587 |
| I(boston[[name]]^3) | -0.00086 | 0.00057 | -1.51702 | 0.129891 |
Variable medv
- Formula: boston$crim ~ boston[[name]] + I(boston[[name]]^2) + I(boston[[name]]^3)
- Residuals
- Coefficients
- Residual standard error: 6.569 on 502 degrees of freedom.
- Multiple \(R^2\): 0.42.
- Adjusted \(R^2\): 0.417.
- F-statistic: 121.272 on 3 and 502, p-value: <2e-16.
| Name | NA_num | Unique | Range | Mean | Variance | Minimum | Q05 | Q10 | Q25 | Q50 | Q75 | Q90 | Q95 | Maximum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Residuals | 0 | 506 | 98.08 | 0 | 42.9 | -24.43 | -6.47 | -4.42 | -1.98 | -0.44 | 0.44 | 3.59 | 7.06 | 73.65 |
| Variable | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| (Intercept) | 53.16554 | 3.35631 | 15.84047 | < 2.22e-16 |
| boston[[name]] | -5.09483 | 0.43383 | -11.74379 | < 2.22e-16 |
| I(boston[[name]]^2) | 0.15550 | 0.01719 | 9.04552 | < 2.22e-16 |
| I(boston[[name]]^3) | -0.00149 | 0.00020 | -7.31197 | 1.0465e-12 |
Some variable are statistically significative until their cubic version (indus, nox, dis, ptratio and medv). So, we can conclude to some non linear relationship between the response and some of the predictors. However, we should also take a look at the colinearity between the predictors because of them seem to be very correlated, and that can change a lot the results.